Performance and Storage Comparison Between Pathfinder and Juno
Reddio has set up nodes through Juno and Pathfinder and is providing Etherum/Starknet RPC service at https://www.reddio.com/node .
This article aims to compare the performance and storage usage between these two nodes. Juno is a Starknet full-node that is written in Go by Nethermind while Pathfinder is another Starknet full-node but is written in Rust by Equilibrium. In order for us to ensure that both of these testing nodes are synchronized to the latest block, we use a cURL request for confirmation:
Juno:
curl -X POST -H "Content-Type: application/json" -d '{"jsonrpc":"2.0","id":0,"method":"starknet_blockHashAndNumber"}' http://localhost:6060
{
"jsonrpc": "2.0",
"result": {
"block_hash": "0x8e366ce31c3e4e34b5b5d31fd0564033966721cf93853a77b3a5741aba5188",
"block_number": 451104
},
"id": 0
}
Pathfinder:
curl -X POST -H "Content-Type: application/json" -d '{"jsonrpc":"2.0","id":0,"method":"starknet_blockHashAndNumber"}' http://localhost:9545
{
"jsonrpc": "2.0",
"result": {
"block_hash": "0x7196ea11a064fc6096f383c171dbb17a27be9870aadedad5b37dc5fd4372602",
"block_number": 451106
},
"id": 0
}
It can be seen that the block_number in both requests differs by only 2, indicating that these two nodes are considered synchronized.
Storage Space
First, let's examine the differences in local storage space between Pathfinder and Juno.
Pathfinder:
total 713G
drwxrwxrwx 2 root root 4.0K Nov 4 11:26 ./
drwxr-xr-x 6 root root 4.0K Nov 14 06:07 ../
-rwxrwxrwx 1 root root 712G Dec 2 04:03 mainnet.sqlite*
-rwxrwxrwx 1 ubuntu ubuntu 1.7M Dec 2 04:03 mainnet.sqlite-shm*
-rwxrwxrwx 1 ubuntu ubuntu 863M Dec 2 04:03 mainnet.sqlite-wal*
Juno:
total 125G
drwxr-xr-x 2 root root 260K Dec 2 04:03 ./
drwxr-xr-x 3 root root 4.0K Dec 2 04:02 ../
-rw-r--r-- 1 root root 8.1M Jul 21 22:41 002540.sst
-rw-r--r-- 1 root root 8.1M Jul 21 22:41 002861.sst
...
-rw-r--r-- 1 root root 3.9M Jul 21 23:05 015018.sst
-rw-r--r-- 1 root root 33M Jul 23 20:03 999203.sst
-rw-r--r-- 1 root root 17 Nov 30 23:40 CURRENT
-rw-r--r-- 1 root root 0 Nov 30 03:58 LOCK
-rw-r--r-- 1 root root 129M Nov 30 23:40 MANIFEST-4682254
-rw-r--r-- 1 root root 110M Dec 2 04:03 MANIFEST-5715011
-rw-r--r-- 1 root root 1.1K Nov 30 03:58 OPTIONS-4682255
It can be observed that there is a significant difference between the two; Pathfinder's storage space usage is 5.7 times more than that of Juno.
Storage Structure
Pathfinder
Pathfinder uses an SQLite database, and the internal table structure can be viewed using SQLite3:
sqlite> .tables
block_headers starknet_events
canonical_blocks starknet_events_keys_03
casm_compiler_versions starknet_events_keys_03_config
casm_definitions starknet_events_keys_03_data
class_commitment_leaves starknet_events_keys_03_docsize
class_definitions starknet_events_keys_03_idx
class_roots starknet_transactions
contract_roots starknet_versions
contract_state_hashes storage_roots
contract_updates storage_updates
l1_state trie_class
nonce_updates trie_contracts
refs trie_storage
The relationships between the various tables are shown in the following diagram:
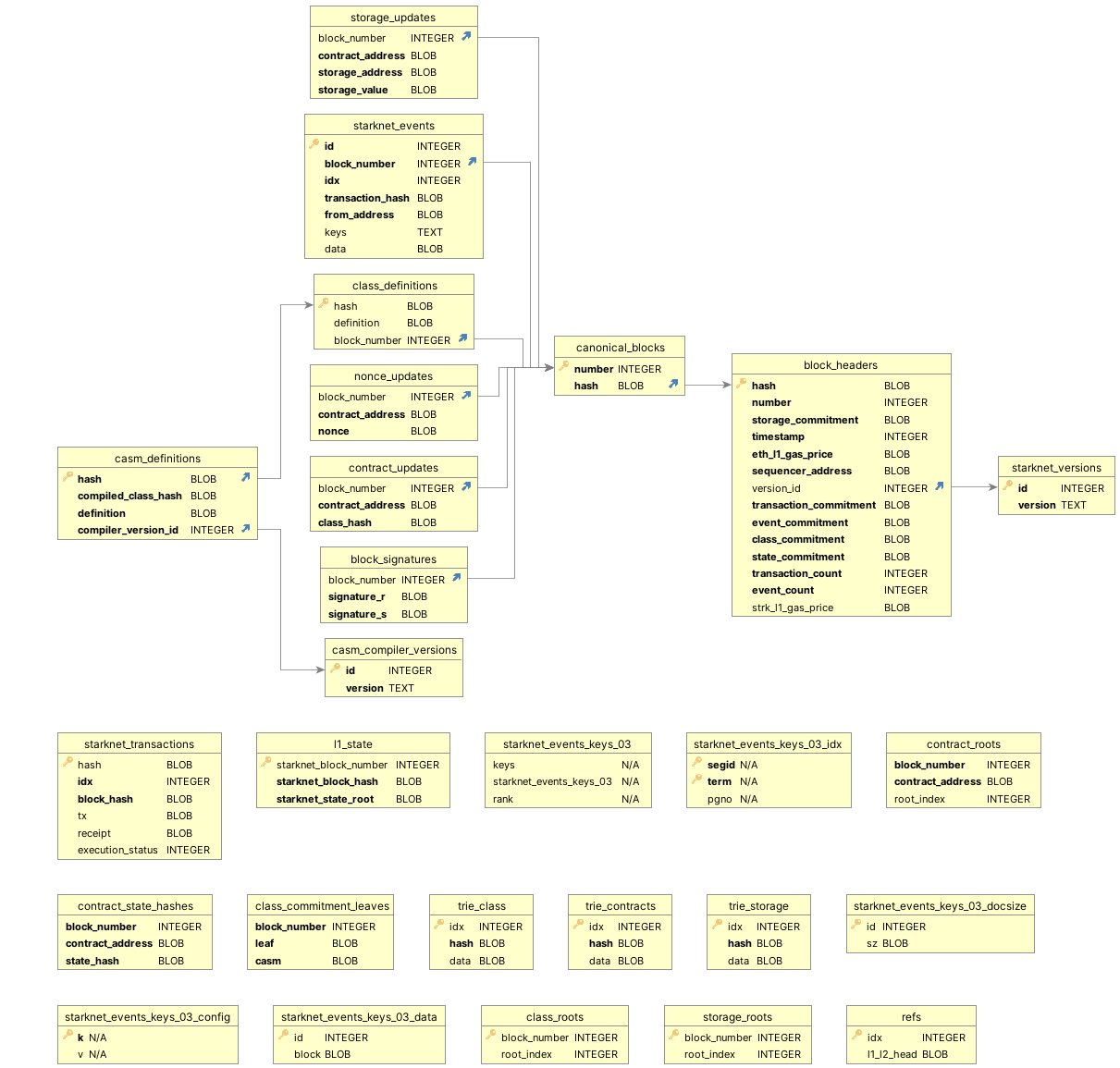
The complete schema can be found at Pathfinder GitHub.
Juno
Juno, using the Pebble KV database, does not follow the relational database table structure. Instead, it uses a prefix mechanism for a similar effect. The corresponding prefixes are defined as follows:
const (
StateTrie Bucket = iota // state metadata (e.g., the state root)
Unused // Previously held contract storage roots and is now unused. May be reused in the future.
ContractClassHash // maps contract addresses and class hashes
ContractStorage // contract storages
Class // maps class hashes to classes
ContractNonce // contract nonce
ChainHeight // Latest height of the blockchain
BlockHeaderNumbersByHash
BlockHeadersByNumber
TransactionBlockNumbersAndIndicesByHash // maps transaction hashes to block number and index
TransactionsByBlockNumberAndIndex // maps block number and index to transaction
ReceiptsByBlockNumberAndIndex // maps block number and index to transaction receipt
StateUpdatesByBlockNumber
ClassesTrie
ContractStorageHistory
ContractNonceHistory
ContractClassHashHistory
ContractDeploymentHeight
L1Height
SchemaVersion
Pending
BlockCommitments
Temporary // used temporarily for migrations
SchemaIntermediateState
)
The relationships between these prefixes create a structure similar to a relational database. A Key function flattens the prefix and a series of byte arrays into a single []byte for KV operations.
Operational Logic
Using a simple request as an example which fetches the latest synced block:
{
"jsonrpc": "2.0",
"id": 0,
"method": "starknet_blockHashAndNumber"
}
Juno
In Juno, this operation is executed as follows:
// BlockHashAndNumber returns the block hash and number of the latest synced block.
//
// It follows the specification defined here:
// https://github.com/starkware
-libs/starknet-specs/blob/a789ccc3432c57777beceaa53a34a7ae2f25fda0/api/starknet_api_openrpc.json#L517
func (h *Handler) BlockHashAndNumber() (*BlockHashAndNumber, *jsonrpc.Error) {
block, err := h.bcReader.Head()
if err != nil {
return nil, ErrNoBlock
}
return &BlockHashAndNumber{Number: block.Number, Hash: block.Hash}, nil
}
The Head function:
func (b *Blockchain) Head() (*core.Block, error) {
b.listener.OnRead("Head")
var h *core.Block
return h, b.database.View(func(txn db.Transaction) error {
var err error
h, err = head(txn)
return err
})
}
...
func head(txn db.Transaction) (*core.Block, error) {
height, err := chainHeight(txn)
if err != nil {
return nil, err
}
return BlockByNumber(txn, height)
}
...
func chainHeight(txn db.Transaction) (uint64, error) {
var height uint64
return height, txn.Get(db.ChainHeight.Key(), func(val []byte) error {
height = binary.BigEndian.Uint64(val)
return nil
})
}
...
// BlockByNumber retrieves a block from the database by its number
func BlockByNumber(txn db.Transaction, number uint64) (*core.Block, error) {
header, err := blockHeaderByNumber(txn, number)
if err != nil {
return nil, err
}
block := new(core.Block)
block.Header = header
block.Transactions, err = transactionsByBlockNumber(txn, number)
if err != nil {
return nil, err
}
block.Receipts, err = receiptsByBlockNumber(txn, number)
if err != nil {
return nil, err
}
return block, nil
}
...
// blockHeaderByNumber retrieves a block header from the database by its number
func blockHeaderByNumber(txn db.Transaction, number uint64) (*core.Header, error) {
numBytes := core.MarshalBlockNumber(number)
var header *core.Header
if err := txn.Get(db.BlockHeadersByNumber.Key(numBytes), func(val []byte) error {
header = new(core.Header)
return encoder.Unmarshal(val, header)
}); err != nil {
return nil, err
}
return header, nil
}
The latest block is retrieved using the txn.Get(db.BlockHeadersByNumber.Key(numBytes)) KV operation.
Pathfinder
Pathfinder follows a more traditional approach with database operations. The relevant code is as follows:
tx.block_id(BlockId::Latest)
.context("Reading latest block hash and number from database")?
.map(|(block_number, block_hash)| BlockHashAndNumber {
block_hash,
block_number,
})
.ok_or(BlockNumberError::NoBlocks)
The block_id function:
BlockId::Latest => tx.inner().query_row(
"SELECT number, hash FROM canonical_blocks ORDER BY number DESC LIMIT 1",
[],
|row| {
let number = row.get_block_number(0)?;
let hash = row.get_block_hash(1)?;
Ok((number, hash))
},
),
This block retrieves the latest block number and hash from the canonical_blocks table using a SQLite query.
Performance Comparison
Merely examining the code doesn't provide an intuitive understanding of the performance difference between the two. To evaluate the performance, a script was written to perform the following:
- Use the
starknet_getBlockWithTxsmethod to randomly request blocks between 0 and the latest block. - Send 1000 requests each to Pathfinder and Juno for this method.
- Pathfinder and Juno use identical machine configurations on Google Cloud:
c3-standard-8with a 2TB SSD persistent disk.
The script:
import requests
import random
import time
url1 = "https://reddio-juno-test.reddio.com"
url2 = "https://reddio-pathfinder-test.reddio.com"
num_requests = 1000
total_time_url1 = 0
total_time_url2 = 0
for _ in range(num_requests):
# Generate a random block number
block_number = random.randint(0, 459353)
# Construct the request payload
payload = {
"jsonrpc": "2.0",
"method": "starknet_getBlockWithTxs",
"params": [{"block_number": block_number}],
"id": 0
}
# Send the request to the first URL
start_time = time.time()
response1 = requests.post(url1, json=payload)
end_time = time.time()
total_time_url1 += end_time - start_time
# Send the request to the second URL
start_time = time.time()
response2 = requests.post(url2, json=payload)
end_time = time.time()
total_time_url2 += end_time - start_time
# Calculate the average response time
average_time_url1 = total_time_url1 / num_requests
average_time_url2 = total_time_url2 / num_requests
# Output results
print(f"Total time for {num_requests} requests to {url1}: {total_time_url1} seconds")
print(f"Average time per request to {url1}: {average_time_url1} seconds")
print(f"\nTotal time for {num_requests} requests to {url2}: {total_time_url2} seconds")
print(f"Average time per request to {url2}: {average_time_url2} seconds")
Execution results:
Total time for 1000 requests to https://reddio-juno-test.reddio.com: 170.26045179367065 seconds
Average time per request to https://reddio-juno-test.reddio.com: 0.17026045179367066 seconds
Total time for 1000 requests to https://reddio-pathfinder-test.reddio.com: 231.7342541217804 seconds
Average time per request to https://reddio-pathfinder-test.reddio.com: 0.2317342541217804 seconds
Juno's response is 35% faster than Pathfinder for this specific load. However, it's essential to note that this is specific to the starknet_getBlockWithTxs method. The performance advantage might not be as pronounced with other types of loads.
We added an additional test:
- Use the
starknet_getEventsmethod to randomly request between 2000 and 459353.
At this point, the code looks like this:
import requests
import random
import time
url1 = "https://reddio-juno-test.reddio.com"
url2 = "https://reddio-pathfinder-test.reddio.com"
num_requests = 500
total_time_url1 = 0
total_time_url2 = 0
for _ in range(num_requests):
# Generate a random block_number
block_number = random.randint(0, 459353)
# Construct Payload for starknet_getBlockWithTxs
payload_getBlock = {
"jsonrpc": "2.0",
"method": "starknet_getBlockWithTxs",
"params": [{"block_number": block_number}],
"id": 0
}
# Send request to the first address for starknet_getBlockWithTxs
start_time = time.time()
response1 = requests.post(url1, json=payload_getBlock)
end_time = time.time()
total_time_url1 += end_time - start_time
# Send request to the second address for starknet_getBlockWithTxs
start_time = time.time()
response2 = requests.post(url2, json=payload_getBlock)
end_time = time.time()
total_time_url2 += end_time - start_time
# Generate random fromBlock and toBlock for starknet_getEvents
from_block = random.randint(0, 2000)
to_block = random.randint(from_block, 459353)
# Construct Payload for starknet_getEvents
payload_getEvents = {
"jsonrpc": "2.0",
"method": "starknet_getEvents",
"params": [
{"fromBlock": from_block, "toBlock": to_block, "page_size": 1000, "page_number": 0, "chunk_size": 10}
],
"id": 1
}
# Send request to the first address for starknet_getEvents
start_time = time.time()
response1 = requests.post(url1, json=payload_getEvents)
end_time = time.time()
total_time_url1 += end_time - start_time
# Send request to the second address for starknet_getEvents
start_time = time.time()
response2 = requests.post(url2, json=payload_getEvents)
end_time = time.time()
total_time_url2 += end_time - start_time
# Calculate average response time
average_time_url1 = total_time_url1 / (2 * num_requests) # Multiply by 2 for the two types of requests
average_time_url2 = total_time_url2 / (2 * num_requests)
# Output results
print(f"Total time for {2 * num_requests} requests to {url1}: {total_time_url1} seconds")
print(f"Average time per request to {url1}: {average_time_url1} seconds")
print(f"\nTotal time for {2 * num_requests} requests to {url2}: {total_time_url2} seconds")
print(f"Average time per request to {url2}: {average_time_url2} seconds")
This time, the results are as follows:
Total time for 1000 requests to https://reddio-juno-test.reddio.com: 102.74015641212463 seconds
Average time per request to https://reddio-juno-test.reddio.com: 0.10274015641212464 seconds
Total time for 1000 requests to https://reddio-pathfinder-test.reddio.com: 108.80669522285461 seconds
Average time per request to https://reddio-pathfinder-test.reddio.com: 0.10880669522285462 seconds
As we can see, in a mixed load scenario involving starknet_getBlockWithTxs and starknet_getEvents, Juno's speed is not as pronounced, only 5% faster than Pathfinder. This also indicates that the performance of the underlying KV may decrease in certain requests. In such cases, if our load balancer can route requests to Juno and Pathfinder based on user requests, we can achieve maximum performance benefits.