Reddio Technology Overview: From Parallel EVM to AI Integration
In the fast-evolving world of blockchain technology, performance optimization has become a critical concern. Ethereum’s roadmap has made it clear that Rollups are central to its scalability strategy. However, the serial nature of EVM transaction processing remains a bottleneck, unable to meet the demands of high-concurrency scenarios of the future.
In a previous article—"Exploring the Path to Parallel EVM Optimization with Reddio"—we provided a brief overview of Reddio’s parallel EVM design. Today, we will delve deeper into its technical solutions and explore scenarios where it intersects with AI.
Since Reddio’s technical framework incorporates CuEVM, a project leveraging GPUs to enhance EVM execution, let’s begin with an introduction to CuEVM.
Overview of CUDA
CuEVM is a project that accelerates EVM using GPUs by translating Ethereum EVM opcodes into CUDA Kernels for parallel execution on NVIDIA GPUs. Leveraging the parallel computing capabilities of GPUs improves the execution efficiency of EVM instructions. CUDA, a term familiar to NVIDIA GPU users, stands for:
Compute Unified Device Architecture, a parallel computing platform and programming model developed by NVIDIA. It enables developers to harness GPU parallel computing for general-purpose computation (such as crypto mining, ZK operations, etc.), beyond just graphics processing.
As an open parallel computing framework, CUDA is essentially an extension of the C/C++ language, allowing any programmer familiar with low-level C/C++ to quickly get started. A key concept in CUDA is the kernel function, a type of C++ function.
// define the kernel function
__global__ void kernel_evm(cgbn_error_report_t *report, CuEVM::evm_instance_t *instances, uint32_t count) {
int32_t instance = (blockIdx.x * blockDim.x + threadIdx.x) / CuEVM::cgbn_tpi;
if (instance >= count) return;
CuEVM::ArithEnv arith(cgbn_no_checks, report, instance);
CuEVM::bn_t test;
}
Unlike regular C++ functions that execute once, kernel functions execute N times in parallel across CUDA threads when invoked using the <<<...>>> syntax.
#ifdef GPU
// TODO remove DEBUG num instances
// num_instances = 1;
printf("Running on GPU %d %d\\n", num_instances, CuEVM::cgbn_tpi);
// run the evm
kernel_evm<<<num_instances, CuEVM::cgbn_tpi>>>(report, instances_data, num_instances);
CUDA_CHECK(cudaDeviceSynchronize());
CUDA_CHECK(cudaGetLastError());
printf("GPU kernel finished\\n");
CGBN_CHECK(report);
Each CUDA thread is assigned a unique thread ID and is organized hierarchically into blocks and grids, which manage a large number of parallel threads. Developers use NVIDIA’s nvcc compiler to compile CUDA code into programs runnable on GPU
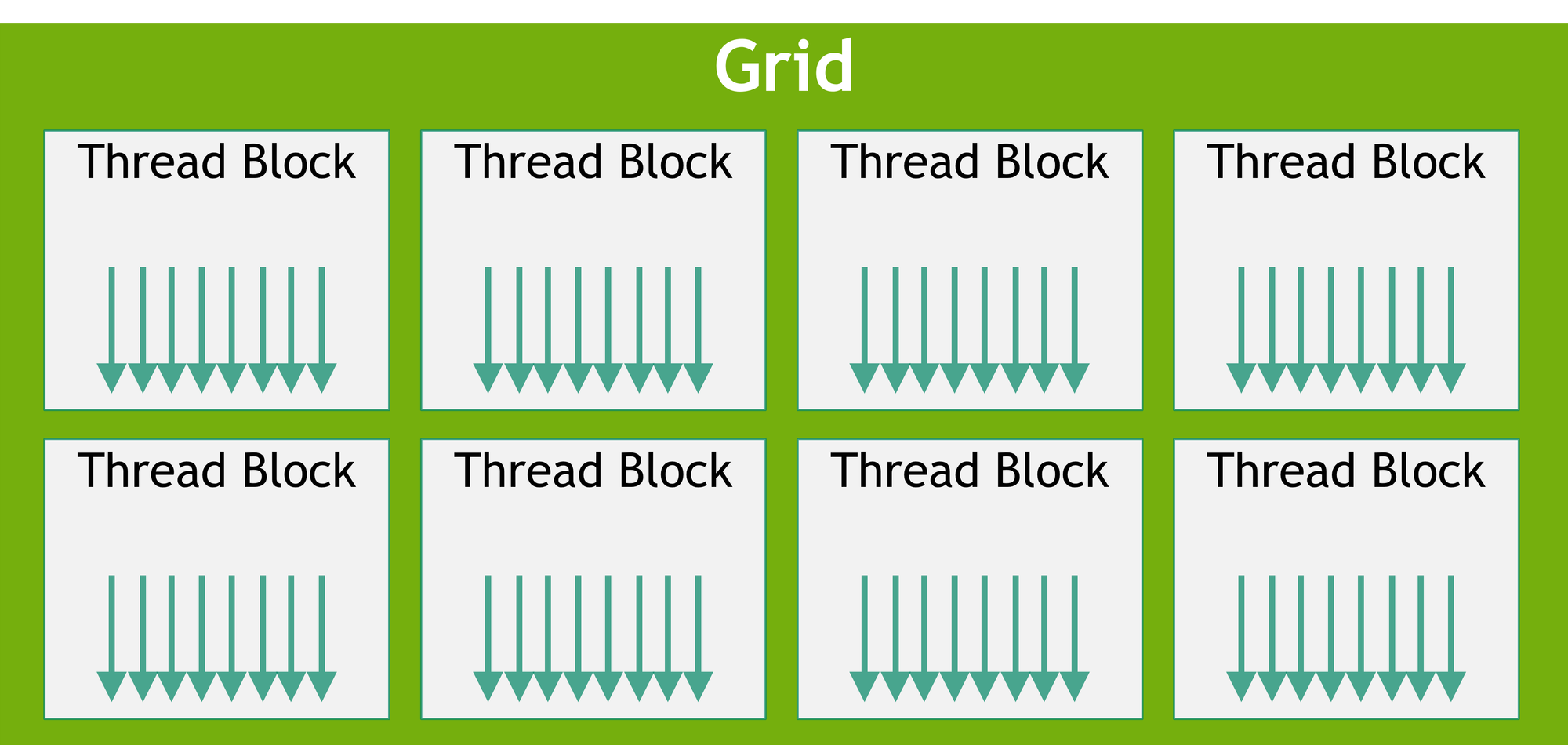
CuEVM Workflow
With a basic understanding of CUDA, we can examine CuEVM’s workflow.
The main entry point of CuEVM is run_interpreter, which accepts transactions to be processed in parallel in the form of a JSON file. The inputs consist of standard EVM content, requiring no additional handling or translation by developers.
void run_interpreter(char *read_json_filename, char *write_json_filename, size_t clones, bool verbose = false) {
CuEVM::evm_instance_t *instances_data;
CuEVM::ArithEnv arith(cgbn_no_checks, 0);
printf("Running the interpreter\\n");
}
Within run_interpreter(), the CUDA-defined <<<...>>> syntax is used to invoke the kernel function kernel_evm(). As mentioned earlier, kernel functions are executed in parallel within the GPU.
void run_interpreter(char *read_json_filename, char *write_json_filename, size_t clones, bool verbose = false) {
cJSON_ArrayForEach(test_json, read_root) {
#ifdef GPU
// TODO remove DEBUG num instances
// num_instances = 1;
printf("Running on GPU %d %d\\n", num_instances, CuEVM::cgbn_tpi);
// run the evm
kernel_evm<<<num_instances, CuEVM::cgbn_tpi>>>(report, instances_data, num_instances);
CUDA_CHECK(cudaDeviceSynchronize());
CUDA_CHECK(cudaGetLastError());
printf("GPU kernel finished\\n");
CGBN_CHECK(report);
#endif
}
}
Inside kernel_evm(), the function evm->run() is called. This function contains numerous branch conditions to convert EVM opcodes into CUDA operations.
namespace CuEVM {
__host__ __device__ void evm_t::run(ArithEnv &arith) {
while (status == ERROR_SUCCESS) {
if ((opcode & 0xF0) == 0x80) { // DUPX
*call_state_ptr->stack_ptr = opcode;
} else if ((opcode & 0xF0) == 0x90) { // SWAPX
error_code = CuEVM::operations::SWAPX(arith, call_state_ptr->gas_limit,
*call_state_ptr->stack_ptr, opcode);
} else if ((opcode >= 0xA0) && (opcode <= 0xA4)) { // LOGX
error_code = CuEVM::operations::LOGX(arith, call_state_ptr->gas_limit,
*call_state_ptr->stack_ptr,
*call_state_ptr->message_ptr, call_state_ptr);
} else {
switch (opcode) {
case OP_STOP:
error_code = CuEVM::operations::STOP(*call_state_ptr->parent->last_op);
break;
case OP_ADD:
error_code = CuEVM::operations::ADD(arith, call_state_ptr->gas_limit,
*call_state_ptr->stack_ptr);
break;
}
}
}
}
}
For example, the EVM opcode OP_ADD (addition) is translated into cgbn_add, utilizing CGBN (Cooperative Groups Big Numbers), a high-performance library for multi-precision integer arithmetic in CUDA.
__host__ __device__ int32_t ADD(ArithEnv &arith, const bn_t gas_used) {
cgbn_add_ui32(arith.env, gas_used, gas_used, GAS_VERIFY);
int32_t error_code = CuEVM::gas_cost::has_gas(arith, gas_used);
if (error_code == ERROR_SUCCESS) {
bn_t a, b, r;
error_code |= stack.pop(arith, a);
error_code |= stack.pop(arith, b);
cgbn_add(arith.env, r, a, b);
error_code |= stack.push(arith, r);
}
return error_code;
}
These steps effectively translate EVM opcodes into CUDA operations. CuEVM implements EVM functionality on CUDA, and the run_interpreter() method ultimately returns the computation results, including the world state and other information.
At this point, the basic logic of CuEVM’s operation has been explained.
While CuEVM is capable of processing transactions in parallel, its primary purpose (and main use case) is fuzzing testing. Fuzzing is an automated software testing technique that inputs large volumes of invalid, unexpected, or random data into a program to observe its behavior, identifying potential bugs and security vulnerabilities.
Fuzzing is inherently suited for parallel processing. However, CuEVM does not handle transaction conflicts, as this is outside its scope. Integrating CuEVM into a system requires external conflict resolution mechanisms.
As discussed in the previous article, Reddio employs a conflict resolution mechanism to sort transactions before feeding them into CuEVM. Thus, Reddio’s L2 transaction sorting mechanism can be divided into two parts: conflict resolution and CuEVM parallel execution.
Layer 2, Parallel EVM, and AI: A Converging Path
Parallel EVM and Layer 2 are only the starting points for Reddio, as its roadmap clearly outlines plans to incorporate AI into its narrative. By leveraging GPU-based high-speed parallel processing, Reddio is inherently well-suited for AI operations:
- GPU’s strong parallel processing capabilities make it ideal for convolution operations in deep learning, which are essentially large-scale matrix multiplications, optimized for GPUs.
- GPU’s hierarchical thread structure corresponds to the data structures in AI computations, utilizing thread over-provisioning and warp execution units to improve efficiency and hide memory latency.
- Computational intensity, a critical metric for AI performance, is enhanced by GPUs through features like Tensor Cores, which improve the efficiency of matrix multiplications, balancing computation and data transmission.
AI and Layer 2 Integration
In Rollup architectures, the network includes not only sequencers but also roles like validators and forwarders that verify or collect transactions. These roles often use the same client software as sequencers but with different functions. In traditional Rollups, these secondary roles are often passive, defensive, and public-service-oriented, with limited profitability.
Reddio plans to adopt a decentralized sequencer architecture where miners provide GPUs as nodes. The Reddio network could evolve from a pure L2 solution into a hybrid L2+AI network, enabling compelling AI + blockchain use cases:
- AI Agent Interaction NetworkAI agents, such as those executing financial transactions, can autonomously make complex decisions and execute high-frequency trades. L1 blockchains cannot handle such transaction loads.Reddio’s GPU-accelerated L2 greatly improves transaction parallelism and throughput, supporting the high-frequency demands of AI agents. It reduces latency and ensures smooth network operation.
- Decentralized Compute MarketIn Reddio’s decentralized sequencer framework, miners compete using GPU resources. The resulting GPU performance levels could support AI training. This market enables individuals and organizations to contribute idle GPU capacity for AI tasks, lowering costs and democratizing AI model development.
- On-chain AI InferenceThe maturation of open-source models has standardized AI inference services. Using GPUs for efficient inference tasks while balancing privacy, latency, and verification (e.g., via ZKP) aligns well with Reddio’s EVM parallelization capabilities.
Conclusion
Layer 2 solutions, parallel EVM, and AI integration may seem unrelated, but Reddio has ingeniously combined them using GPU computing. By enhancing transaction speed and efficiency on Layer 2, Reddio improves Ethereum’s scalability. Integrating AI opens new possibilities for intelligent blockchain applications, fostering innovation across industries.
Despite its promise, this domain is still in its infancy and requires substantial research and development. Continued iteration, market imagination, and proactive action from pioneers like Reddio will drive the maturity of this innovation. At this critical intersection, Reddio has taken bold steps, and we look forward to more breakthroughs in this space.