Optimizing the timeout issue in Geth when querying large-span sparse logs through KV.
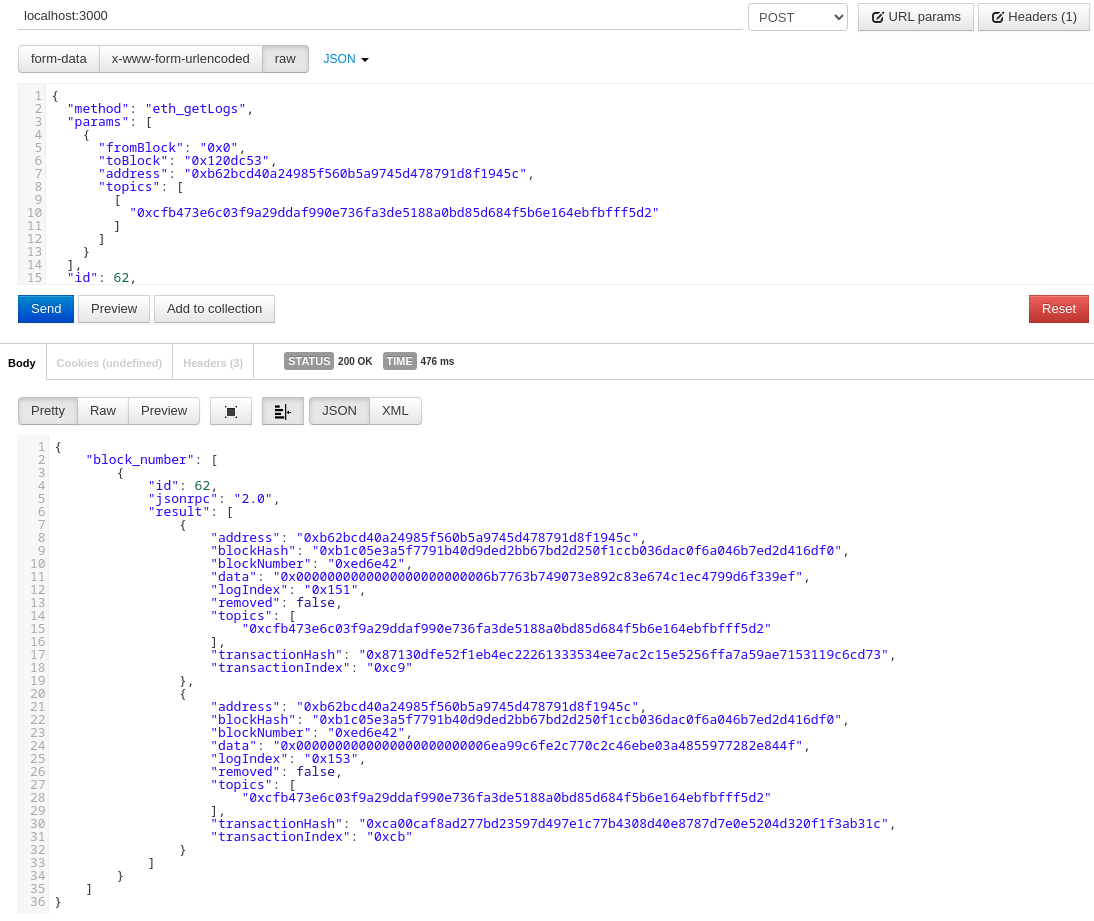
Before we begin, let's take a look at a request sent to Geth:
{
"method": "eth_getLogs",
"params": [
{
"fromBlock": "0x0",
"toBlock": "0x120dc53",
"address": "0xb62bcd40a24985f560b5a9745d478791d8f1945c",
"topics": [
[
"0xcfb473e6c03f9a29ddaf990e736fa3de5188a0bd85d684f5b6e164ebfbfff5d2"
]
]
}
],
"id": 62,
"jsonrpc": "2.0"
}
The semantics of this request are clear: it searches for logs with the topic "0xcfb473e6c03f9a29ddaf990e736fa3de5188a0bd85d684f5b6e164ebfbfff5d2" on the address "0xb62bcd40a24985f560b5a9745d478791d8f1945c" from block 0x0 to block 0x120dc53 (decimal 18930771) in the entire Ethereum blockchain.
However, when we send this request to our own ETH node, we experience a 30-second wait time followed by a timeout response:
{
"jsonrpc": "2.0",
"id": 62,
"error": {
"code": -32002,
"message": "request timed out"
}
}
Why is this happening?
To understand the reason behind this, we need to start with the working mechanism of Geth for the eth_getLogs query.
Bloom Filter
In Ethereum, there is a data structure called the Bloom filter.
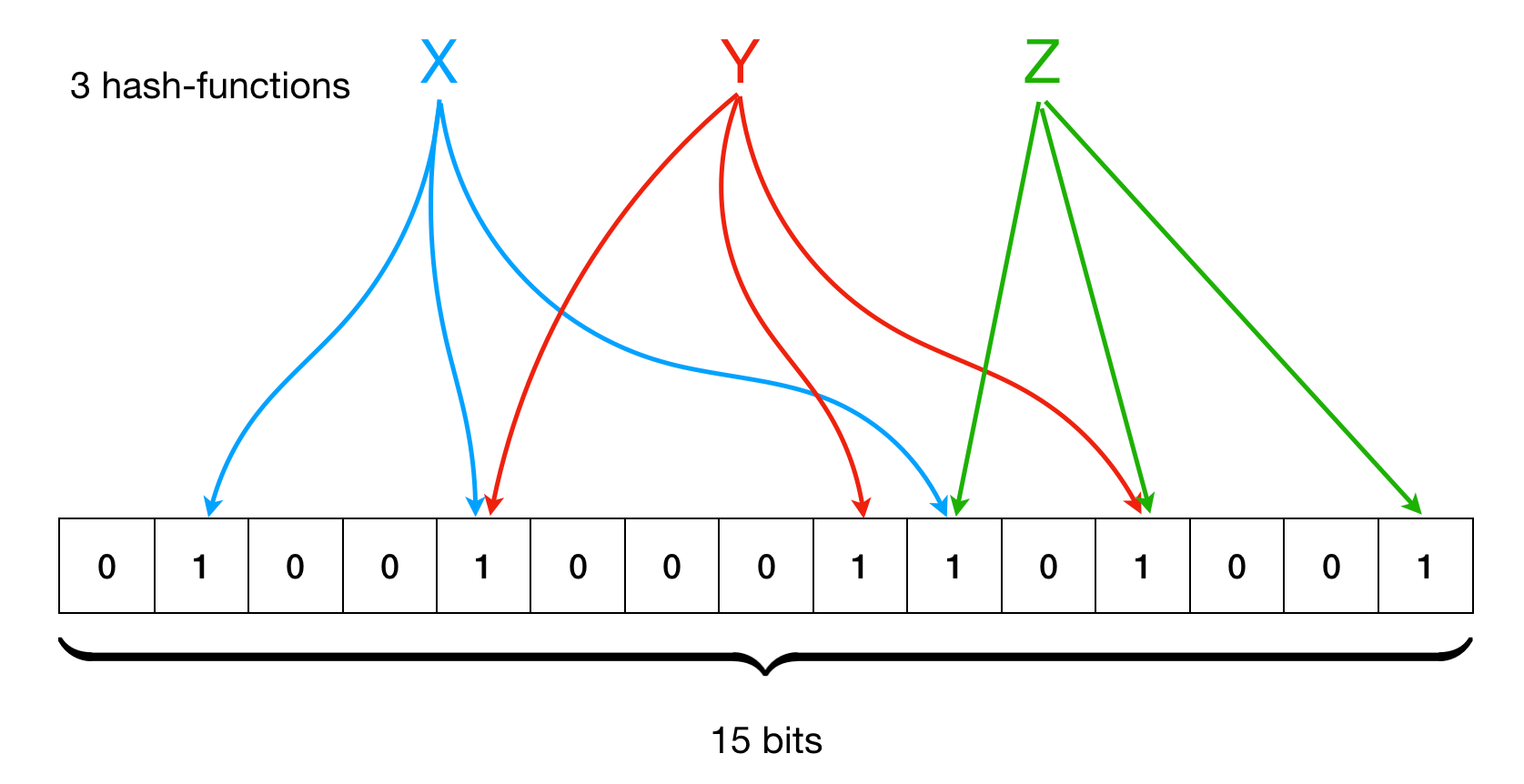
- Bloom Filter is a probabilistic data structure used to quickly determine whether an element belongs to a set. It is often used to efficiently check if an element exists in a large dataset without actually storing the entire dataset.
- The core idea of a Bloom Filter is to use multiple hash functions and a bit array to represent elements in the set. When an element is added to the Bloom Filter, its hash values from multiple hash functions are mapped to corresponding positions in the bit array, and these positions are set to 1. When checking if an element exists in the Bloom Filter, the hash values of the element are again mapped to the corresponding positions in the bit array, and if all positions are 1, it is considered that the element may exist in the set, although there may be a certain probability of false positives.
- The advantages of Bloom Filters are that they occupy relatively small space and provide very fast membership tests. They are suitable for scenarios where a certain false positive rate can be tolerated, such as fast retrieval or filtering in large-scale datasets.
In Ethereum, the Bloom filter for each block is calculated based on the transaction logs in the block.
In each Ethereum block, transaction logs are an important part where contract events and state changes are stored. The Bloom filter is constructed by processing the data in the transaction logs. Specifically, for each transaction log, it extracts key information such as the contract address and log data. Then, using hash functions, it converts this information into a series of bit array indices and sets the corresponding positions in the bit array to 1.
In this way, each block has a Bloom filter that contains the key information from the transaction logs. When querying for a specific contract address or other information related to the transaction logs in a block, the Bloom filter can be used to quickly determine whether the relevant information exists. This query method improves efficiency by avoiding direct access and processing of a large amount of transaction log data.
We can see the Bloom value of a specific block by sending the following request:
{"method":"eth_getBlockByNumber","params":["latest",false],"id":1,"jsonrpc":"2.0"}
The response is as follows:
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"baseFeePerGas": "0xbf7b14fbe",
...
"hash": "0x86f79ed4401eb79c899c3029c54c679fd91f22c6b81a651c78c0f664b1316ce6",
"logsBloom": "0xf4b37367e1d1dd2f9fb1e3b298b7fe61e7f40b0dbc71fcf4af5b1037f67238294d3257ffd35b2f3dcde1db20fb77139edb3f086cff3a79bda56575baac7ead457a4ef95c7fc7bf7afec2e00fbeaae6ff5daa5a9d8b5698ce5bfdf66ac8741c3e9e4d364c1e631dc326cdfe97fc6bfedfe2ae47fb14aeb70d938b5dde00dac77aab17bad6976ddedd30c5a57a3bcd563f826dc319d9914dea66614dee59d5346a8b7a076c63966af73ee7d7f4daffac4c86ff9f79c90efd82c5ab3d8299bb04f874d1a4420c3f4ef825dc0b0b2a6e7b434da4b74f0d6b9816a87eed4f35323d0094f8ee2e33531560db2e7feebe191a888da87499f9ff555cbc5f9e36e89dbd07",
"stateRoot": "0x48f5a24f3f42d5f5650fbaaccf6713ba0b85d371e0ec7c5d5e1d16df47"
}The logsBloom field in the response represents the Bloom filter value of that block. Its length is 512 hexadecimal characters, which corresponds to 2048 bits in binary.
So, when we want to query for a specific topic, Geth calculates the Bloom filter needed based on the topic and then iterates through the logsBloom field of each block within the specified range (from fromBlock to toBlock) to determine if the block may contain the corresponding log.
It is important to note that due to the probabilistic nature of Bloom filters and the limited size of the Bloom filter (2048 bits) compared to the vast number of blocks in Ethereum, there will be a large number of blocks that may result in false positives. This means that the Bloom filter may match, but the actual log may not exist in those blocks, leading to a significant amount of query time and even timeouts.
This issue has been discussed in the Geth GitHub repository, for example:
- https://github.com/ethereum/go-ethereum/issues/25336
- https://github.com/ethereum/go-ethereum/issues/28765
However, there hasn't been a mature solution yet. One approach discussed is to increase the length of the Bloom filter. Another approach is to introduce a subscription mechanism where clients can subscribe to similar requests and allow Geth to query in the background without requiring synchronous queries that may result in timeouts.
Reverse KV
This article attempts to propose an approach to mitigate this issue, and we have observed its effectiveness in our internal Proof of Concept (PoC). For the previous example provided, where we are searching for logs with the topic "0xcfb473e6c03f9a29ddaf990e736fa3de5188a0bd85d684f5b6e164ebfbfff5d2" on the address "0xb62bcd40a24985f560b5a9745d478791d8f1945c", which is very sparse (only two records), we can use a caching layer that maps topics to the blocks where they exist.
For example, for the given topic, we can store the value as the block number "0xed6e42" (decimal 15560258).
In this way, when we encounter a similar request, we can quickly determine the block where the log exists based on the topic and reassemble the request. In this case, since we already know that the log is in block "0xed6e42", we can modify the request as follows (note that both fromBlock and toBlock are set to "0xed6e42"):
{
"method": "eth_getLogs",
"params": [
{
"fromBlock": "0xed6e42",
"toBlock": "0xed6e42",
"address": "0xb62bcd40a24985f560b5a9745d478791d8f1945c",
"topics": [
[
"0xcfb473e6c03f9a29ddaf990e736fa3de5188a0bd85d684f5b6e164ebfbfff5d2"
]
]
}
],
"id": 62,
"jsonrpc": "2.0"
}
We can then send the modified requests to the actual Geth backend, optimizing the response time.
Implementation
Our key-value (KV) storage implementation uses Pebble, a Go implementation similar to LevelDB/RocksDB, which is also the underlying storage implementation for Juno.
Block
To implement storage, we first need to fetch blocks. Since we have our own ETH node, we can start fetching blocks from the first block on our node. The key code snippet is as follows:
if LatestBlockNumberInDBKey < LatestBlockNumberOnChain {
for i := LatestBlockNumberInDBKey; i < LatestBlockNumberOnChain; i++ {
fmt.Println("Dealing with block number: ", i)
// Get topic list from block number
topicList, err := getTopicListByBlockNumber(i)
if err != nil {
fmt.Printf("Failed to get topic list: %v\n", err)
// Retry
return
}
fmt.Printf("Total topics: %d\n", len(topicList))
if len(topicList) > 0 {
for _, topic := range topicList {
SetKeyNumberArray(topic, i)
}
// Flush DB
FlushDB()
}
// Update LatestBlockNumberInDB
SetKeyNumber("LatestBlockNumberInDB", i)
}
}
Since the value in Pebble is a byte array, we need two helper functions:
func SetKeyNumberArray(key string, number uint64) error {
// Check if key exists, if exists, read array and append number to array
// If not exists, create array with number
keyByteSlice := []byte(key)
existingNumberArray, err := GetKeyNumberArray(key)
if err != nil {
return err
}
if existingNumberArray != nil {
// Append number to array
existingNumberArray = append(existingNumberArray, number)
// Deduplicate array
existingNumberArray = DeduplicateUint64Array(existingNumberArray)
numberByteSlice := Uint64ArrayToByteSlice(existingNumberArray)
err := DB.Set(keyByteSlice, numberByteSlice, pebble.NoSync)
if err != nil {
return err
}
return nil
} else {
// Create array with number
numberArray := []uint64{number}
numberByteSlice := Uint64ArrayToByteSlice(numberArray)
err := DB.Set(keyByteSlice, numberByteSlice, pebble.NoSync)
if err != nil {
return err
}
return nil
}
}
func GetKeyNumberArray(key string) ([]uint64, error) {
keyByteSlice := []byte(key)
value, closer, err := DB.Get(keyByteSlice)
if err != nil {
// Check if key is not found
if err == pebble.ErrNotFound {
return nil, nil
}
return nil, err
}
defer closer.Close()
numberArray := ByteSliceToUint64Array(value)
return numberArray, nil
}
Since we aim for performance during the Set operation, we use pebble.NoSync mode for writing. After processing each block, we manually call FlushDB to flush the writes to disk.
Handler
Once we have fetched the blocks, we can handle user POST requests. The general approach is as follows:
- Parse the user's POST request. If the request is for
eth_getLogs, split the user's topics and query the KV database. - Retrieve the corresponding block range from the KV database based on the topics.
- Consolidate the block range.
- Reassemble the user's request by replacing
fromBlockandtoBlockwith the consolidated block range. - Send the reassembled requests to the Geth backend and concatenate the returned data.
- Return the data to the user.
Demo
In our local environment, we verified that with this KV caching layer, the above query can return results in approximately 450ms (note that the majority of the 450ms is the round-trip time (RTT) between the local environment and our ETH node, while the actual KV response speed is within 20ms).
Future Plans
In the example above, we have completed a PoC for optimization. However, there are still several areas that need improvement, such as:
- Handling multiple topic intersections and queries
- Dealing with large block ranges for a specific topic, where the caching layer needs to be able to prevent requests from reaching the actual Geth backend to avoid excessive backend pressure
We have already deployed this caching layer on an internal test node and open-sourced the program on GitHub at: https://github.com/reddio-com/eth_logcache. We welcome interested individuals to use it and contribute to further its development.