How Reddio builds a globally low-latency Starknet RPC node service
In this article, we discuss how we set up these services and how we achieve a much lower global average response latency.
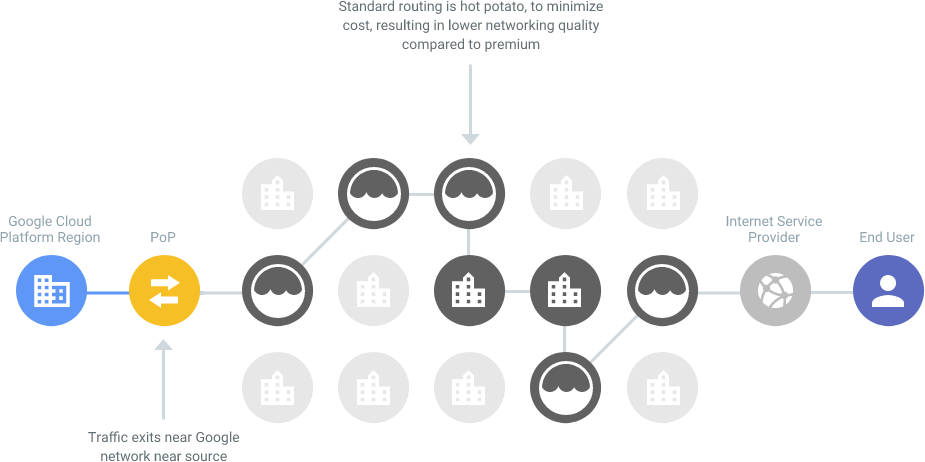
In the previous two articles, ETH Full Node and Pathfinder and Reddio's Starknet Beta Node Launch: Access the Future Today, we shared the methods for setting up ETH nodes and Starknet nodes, as well as the services we offer to the public. In this article, we will discuss how we set up these services and how we achieve a much lower global average response latency.
Node Setup
Our method of setting up nodes involves using the approach described in our own blog, ETH Full Node and Pathfinder. All nodes are located on Google Cloud, utilizing Google Cloud's SSD Persistent Disk to ensure fast disk IO speeds.
Network
Since we use Google Cloud, we have adopted the Premium Network (Google Cloud Network Tiers) for our machines' network. Google's Premium Network ensures that most of the traffic stays within Google's global network, reducing the latency caused by routing traffic over the public internet.
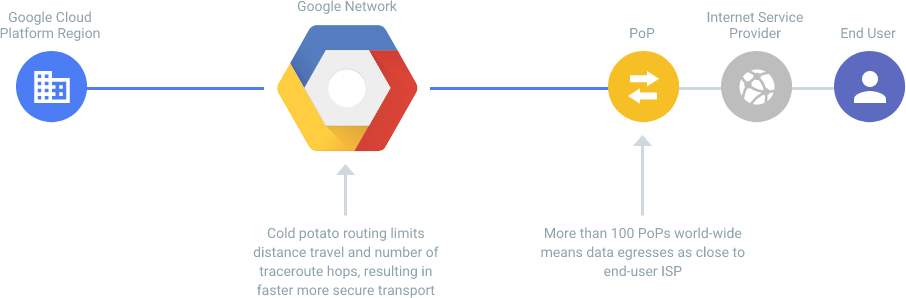
Compared to other standard service providers, where traffic typically hits the public internet after leaving the provider's network (as illustrated in the example), using Google Premium Network has improved our nodes' network stability and latency.
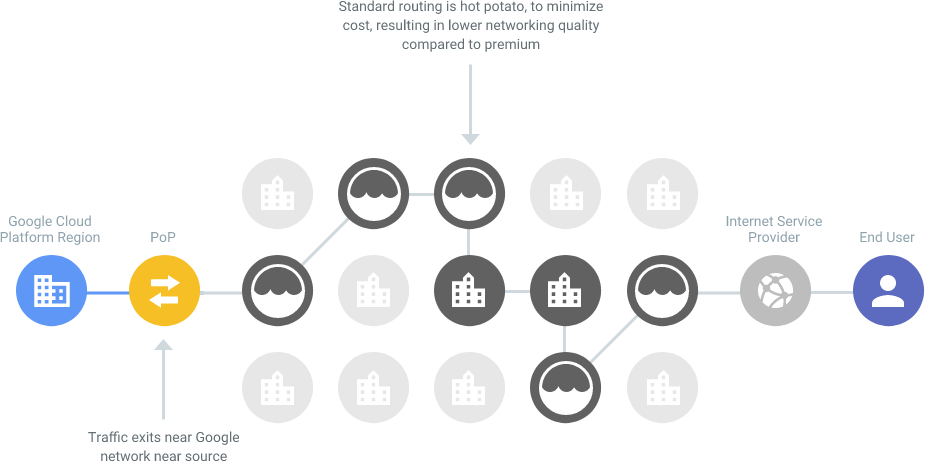
Global Load Balancing
Using just the Premium Network gives us certain advantages in regional networks, but global network latency is still inevitable. For instance, if all our nodes were in the United States (like Infura):
- For US users, accessing https://starknet-mainnet.reddio.com would first route traffic through Cloudflare's US nodes (since we use Cloudflare's CDN as a front CDN), and then from Cloudflare US to Google Cloud nodes over the public internet, resulting in minimal latency.
- For European users, the traffic would first hit Cloudflare's European nodes, then travel over the public internet to the US Google Cloud nodes, incurring at least 150ms of one-way latency, or 300ms round trip. This amount of delay is unacceptable for a large volume of requests.
To ensure we only need to provide one URL (https://starknet-mainnet.reddio.com) but still offer much lower access latency for users in different countries, we used Cloudflare Workers for load balancing. After implementing Cloudflare Workers, the process is as follows:
- When US users access Cloudflare's US nodes, our Workers detect the user is from the US and route the traffic to the US Google Cloud.
- When European users access Cloudflare's European nodes, Workers detect the user's European country and route the traffic to our nodes in European Google Cloud (specifically in Frankfurt).
Here's a part of the Workers code:
export default {
async fetch(request, env, ctx) {
let payload = "";
if (request.method === "POST") {
payload = await request.json();
}
const CF_IP_COUNTRY = request.headers.get('cf-ipcountry');
// Determine Continent by CF_IP_COUNTRY
const continent = getContinentByISOCode(CF_IP_COUNTRY);
const backend_url = BACKEND_MAP[continent];
return handleProxy(request, backend_url, payload, CF_IP_COUNTRY);
},
};
Additionally, we use Workers' scheduled (Cloudflare Workers Runtime APIs - Scheduled) for availability checks and block monitoring on each node (e.g., to determine if any node is N blocks behind, in which case we send an alert to our Slack Channel).
Thus, we only need to deploy nodes in major continents (currently, we have nodes in the Americas (USA), Asia (Singapore), and Europe (Germany)). By integrating Cloudflare Workers for load balancing and failover, we have provided a Starknet node with very low global latency.
Here's a table showing the latency measurements from various locations:
| Location | DNS | Connect | TLS | TTFB |
|---|---|---|---|---|
| Frankfurt | 10.34 ms | 0.74 ms | 20.66 ms | 89.92 ms |
| Amsterdam | 27.53 ms | 2.78 ms | 17.4 ms | 106.92 ms |
| London | 15.19 ms | 3.03 ms | 17.51 ms | 117.73 ms |
| New York | 28.6 ms | 1.95 ms | 27.57 ms | 159.83 ms |
| San Francisco | 19.36 ms | 2.62 ms | 24.49 ms | 240.89 ms |
Compared to Infura's nodes, which seem to have slightly lower response latency only in the United States (presumably because their nodes are all located there), the difference is noticeable:
| Location | DNS | Connect | TLS | TTFB |
|---|---|---|---|---|
| Frankfurt | 19.85 ms | 92.27 ms | 198.68 ms | 385.15 ms |
| Amsterdam | 7.65 ms | 99.14 ms | 210.11 ms | 407.72 ms |
| London | 7.86 ms | 81.94 ms | 171.83 ms | 336.58 ms |
| New York | 15.55 ms | 7.47 ms | 32.42 ms | 48.85 ms |
| San Francisco | 17.59 ms | 72.54 ms | 156.74 ms | 302.38 ms |
Besides the TTFB (Time To First Byte) test, the actual response speed for query requests is also a crucial metric. We conducted tests using the ethspam and versus tools, with the test location being Google Cloud in Germany:
Infura node test results:
./ethspam --rpc="<https://mainnet.infura.io/v3/><OUR_INFURA_KEY>" | ./versus --stop-after=1000 --concurrency=5 "<https://mainnet.infura.io/v3/><OUR_INFURA_KEY>"
Endpoints:
0. "<https://mainnet.infura.io/v3/><OUR_INFURA_KEY>"
Requests: 51.42 per second
Timing: 0.0972s avg, 0.0901s min, 0.5077s max
0.0261s standard deviation
Percentiles:
25% in 0.0928s
50% in 0.0940s
75% in 0.0955s
90% in 0.0976s
95% in 0.1013s
99% in 0.1716s
Errors: 0.00%
** Summary for 1 endpoint:
Completed: 1000 results with 1000 total requests
Timing: 97.233598ms request avg, 20.056031219s total run time
Errors: 0 (0.00%)
Mismatched: 0
Our ETH mainnet node test results:
./ethspam --rpc="<https://eth-mainnet.reddio.com>" | ./versus --stop-after=1000 --concurrency=5 "<https://eth-mainnet.reddio.com>"
Endpoints:
0. "<https://eth-mainnet.reddio.com>"
Requests: 154.83 per second
Timing: 0.0323s avg, 0.0146s min, 3.0198s max
0.1146s standard deviation
Percentiles:
25% in 0.0171s
50% in 0.0186s
75% in 0.0214s
90% in 0.0280s
95% in 0.0724s
99% in 0.2682s
Errors: 0.00%
** Summary for 1 endpoint:
Completed: 1000 results with 1000 total requests
Timing: 32.293368ms request avg, 8.733759725s total run time
Errors: 0 (0.00%)
Mismatched: 0
From our tests in Germany, it's evident that our RPS (Requests Per Second) is three times than Infura.
Based on similar logic, we currently provide the following low-latency global nodes:
- ETH Mainnet: https://eth-mainnet.reddio.com
- ETH Sepolia: https://eth-sepolia.reddio.com
- Starknet Mainnet: https://starknet-mainnet.reddio.com
- Starknet Goerli: https://starknet-goerli.reddio.com (Starknet Alpha version on Goerli testnet 1)
Of course, this is just our first step in providing node services. As seen in the comparison charts, our US nodes have slightly higher latency during tests than Infura's, which could be due to the load on the test nodes or the startup time of Workers. We are continuously optimizing this, and in the future, we plan to provide low-latency services in Oceania (Australia) as well.
Stay tuned!
Low latency and free Starknet node awaits!
For a limited time, Reddio is offering unrestricted access to its high-speed StarkNet Node, completely free of charge. This is an unparalleled opportunity to experience the fastest connection with the lowest delay. All you need to do is register an account on Reddio at https://dashboard.reddio.com/ and start exploring the limitless possibilities.